

{kind=link}
Introduction
Tracking systems play a crucial role in modern transportation and logistics. They provide valuable insights into the location, status, and performance of pilots, trucks, aircraft, and other vehicles, as well as simplify their management and reinforce safety.
However, developing robust tracking systems presents a significant challenge because they need to work well under different conditions, including heavy loads.
In this article, we’ll investigate the creation of robust tracking systems by presenting two different ways and examples of building them. Each approach uses its own set of technologies suited to particular situations and needs.
Overview of Common Approaches to Building Tracking Systems
All modern tracking systems vary in terms of technology, scalability, and features, but they all share the common goal of providing accurate and trustworthy tracking capabilities.
Creating tracking systems involves managing various data sources, handling large data volumes in real-time, and ensuring reliability and performance. Here are some common ways to do it:
Real-Time Data Input
Tracking systems need to handle data as it comes in, ensuring no information gets lost or delayed. Technologies like Apache Kafka or AWS Kinesis help manage this continuous flow of data efficiently.
Data Storage and Management
Different tracking systems use different types of databases to store their information. Some rely on traditional databases like PostgreSQL or SQL Server for structured data, while others prefer NoSQL databases like Cassandra or MongoDB for their flexibility with unstructured data.
System Reliability
It’s crucial for tracking systems to stay operational even if certain components fail. Strategies like database replication and load balancing help ensure uninterrupted service and prevent disruptions in data collection and processing.
Scalability Demands
Tracking systems need to be able to handle instabilities in data volume and user activity. They must scale up during peak periods and scale down during quieter times to maintain optimal performance without overloading resources.
User Interface
Users need intuitive interfaces to access and interpret tracking data effectively. Building interfaces with Spring Boot or React helps create user-friendly experiences that simplify data visualization and analysis.
Deployment
Tracking systems can be deployed on various platforms, from cloud services like AWS or Google Cloud to in-house servers. Each option has its advantages and considerations, such as scalability, cost, and control over infrastructure.
Data Security
Since tracking systems deal with sensitive information, they must prioritize data security. Implementing measures like encryption and access controls helps protect data integrity and confidentiality, ensuring compliance with security regulations.
System Performance
Continuous monitoring of system performance is essential to detect and address issues promptly. Monitoring tools like Prometheus or Grafana provide insights into system health and performance metrics, enabling proactive maintenance and troubleshooting.
Approach 1: Java-Kafka-Cassandra
Solution Example: High-Load Multi-Tenant Tracking System
Technology Stack: Java, Kafka, Cassandra, PostgreSQL, ELK, Spring Boot
Approach Overview
The first approach is well-suited for building a high-frequency, multi-tenant tracking system resembling the operational complexity of an airport, encompassing various elements such as planes, service machinery like fuel tanks, buses, luggage carriers, and more.
By using technologies like Kafka, Cassandra, and Spring Boot, it ensures robustness, scalability, and performance while providing a user-friendly interface for data visualization and analysis.
Let’s break down how each aspect works.
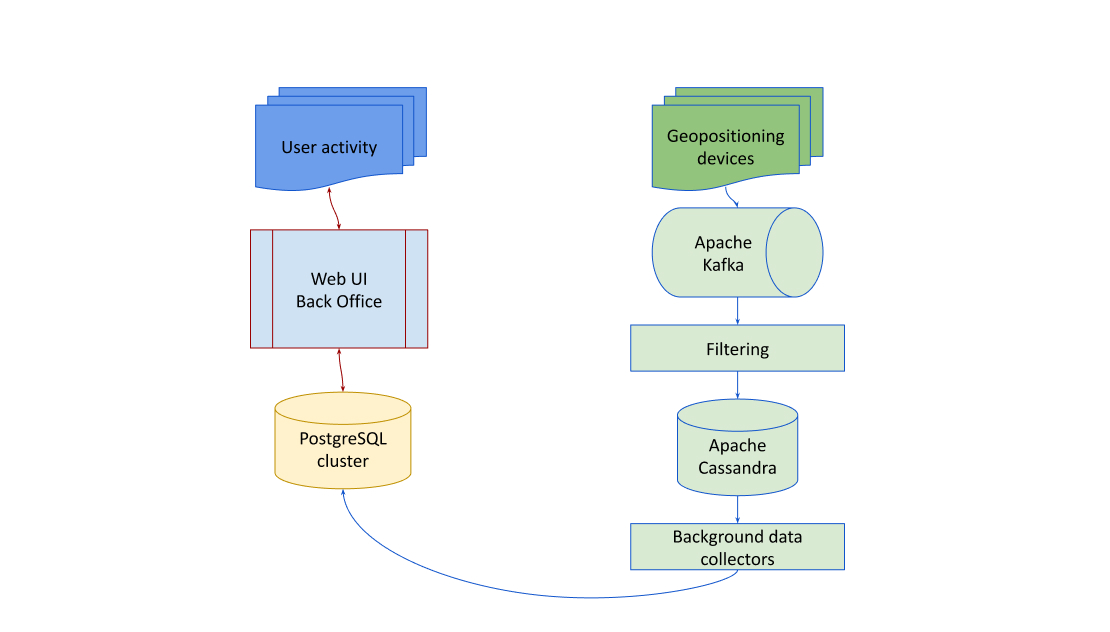
Hadoop-Based Stack for Scalability
Using a Hadoop-based stack ensures scalability and prevents system overload, particularly in scenarios with a high frequency of tracking points. Hadoop’s distributed processing capabilities allow the system to handle large volumes of data without compromising performance.
Application Architecture
The application architecture comprises three main parts:
- A rich UI application built using Java and Spring Boot, providing features such as reports, analytics, and dashboards.
- PostgreSQL is used for structured data storage, facilitating data querying and retrieval.
- A load balancer is deployed in front of the application to evenly distribute incoming traffic across multiple instances, improving scalability and fault tolerance.
High-Frequency Data Processing with Kafka
Kafka is chosen as the primary data ingestion and processing tool due to its reliability and scalability, particularly for handling high-frequency data streams.
Basic data filtering mechanisms are applied on top of data consumption to manage the influx of data.
Once filtered, the data is streamed to Cassandra, a highly scalable NoSQL database, in a denormalized format. This approach optimizes querying performance and storage efficiency.
Schedule-Based Background Tasks
Scheduled tasks are implemented to collect data from Cassandra and transform it into a user-friendly format suitable for reporting and analysis. These tasks ensure regular updates and availability of data for consumption by the rich UI application, enhancing the overall user experience.
If we’ll go deeper, the scheme will look like this:
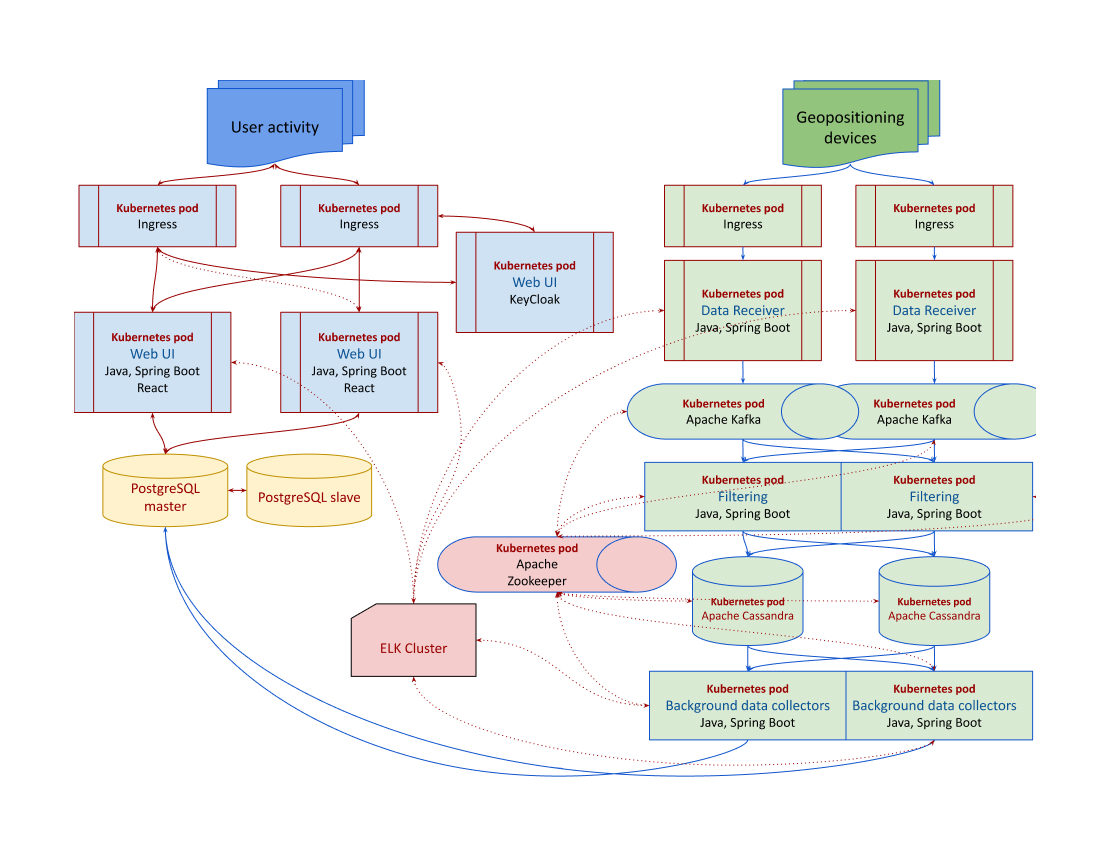
Verdict
In summary, building a tracking system using the Java-Kafka-Cassandra approach involves designing a scalable and fault-tolerant architecture capable of handling high-frequency data streams.
By applying technologies like Kafka for data processing and Cassandra for storage, coupled with a robust application architecture and scheduled background tasks, the system can efficiently manage tracking data while providing users with actionable insights through a user-friendly interface.
Approach 2: .NET-MS SQL-MongoDB
Solution Example: Truck Tracking System
Technology Stack: .NET, MS SQL, MongoDB, Windows Server, Linux (NGINX)
Approach Overview
Building a tracking system using the .NET, MS SQL, and MongoDB approach involves tailoring the system to track vehicles with less stringent requirements compared to previous solutions.
Here’s how the architecture and infrastructure work:
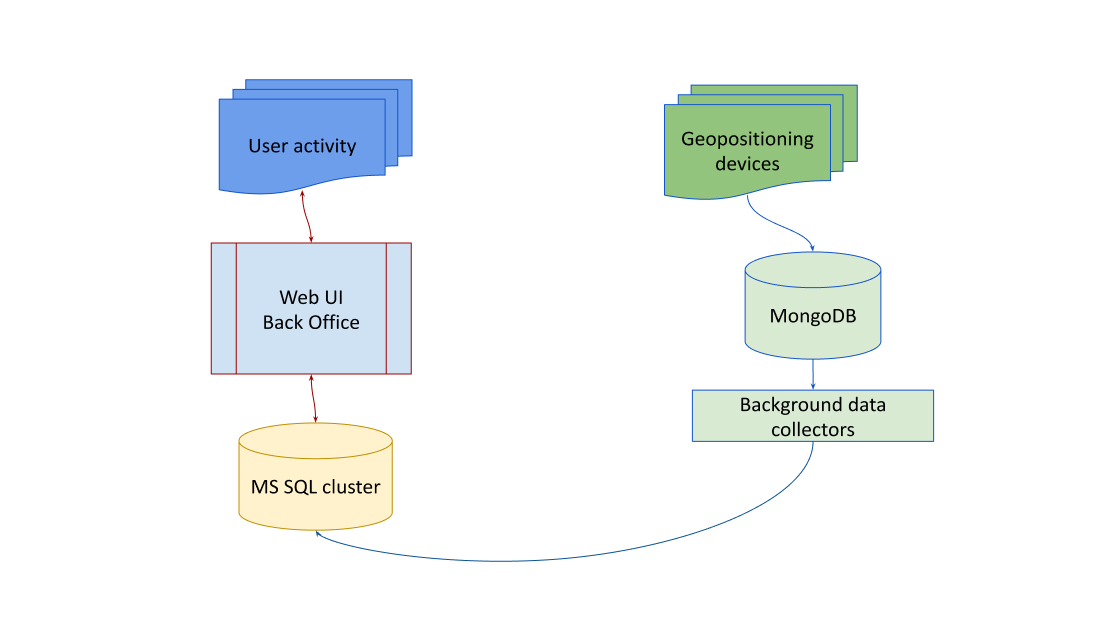
Microsoft-Specific Infrastructure
The infrastructure is Microsoft-specific, using technologies, such as Active Directory for user authentication and authorization.
Shared disks and network cards are utilized for the MS SQL Always-On cluster, providing high availability and fault tolerance.
The system employs two active nodes along with other components, adhering to standard MS monitoring practices.
VMWare vSphere Deployment
VMWare vSphere is used behind the scenes, deploying each element of the system as a separate virtual machine.
Windows Server is the preferred operating system for most components, except for MongoDB and NGINX, which run on Linux boxes.
Classic Cluster Architecture
The architecture resembles a classic cluster setup, devoid of modern Kubernetes or Dockerization.
Initially, there were no Linux boxes, but subsequent adjustments were made to address specific issues encountered post-launch.
Addressing Performance and Backup Issues
CPU consumption by LSAss due to HTTPS processing and unpredictable backup times for MongoDB were identified as key issues.
A separate VM with Linux and NGINX was launched to offload HTTPS traffic processing, mitigating CPU consumption.
To address backup issues, three MongoDB instances were implemented: one master and two slaves. When a backup is needed, one of the slave nodes detaches from the cluster, allowing for quick backups to be performed. The node is then reattached as a slave.
Verdict
This approach applies the .NET framework, MS SQL, and MongoDB to build a tracking system tailored with fewer requirements.
The Microsoft-specific infrastructure, VMWare vSphere deployment, and classic cluster architecture provide a reliable foundation for the system. Addressing performance and backup issues ensures the system operates efficiently and maintains data integrity.
Bottom Line
Both solutions offer robust tracking systems catering to different requirements and load scenarios.
Approach 1 uses a scalable, multi-tenant architecture with high-frequency data processing, while Approach 2 adopts a Microsoft-specific infrastructure with enhancements to address performance and backup challenges.
These architectures provide reliable tracking solutions for pilots and vehicles in diverse operational environments, ensuring scalability, reliability, and performance.