

{kind=link}
Before we begin, let’s read this excerpt from the book.
Distributed systems are often complex pieces of software of which the components are by definition dispersed across multiple machines. To master their
complexity, it is crucial that these systems are
properly organized.
There are different ways on how to view the organization of a distributed system, but an obvious one is to make a distinction between the logical organization of the collection
of software components and on the other hand the actual physical realization.
Guys, it’s important to understand this, these are the basics, this is the root of your understanding of how to build such systems so that they are as fault-tolerant as possible.
Using components and connectors, we can come to various configurations, which, in tum have been classified into architectural styles. Several styles have by now been identified, of which the most important ones for distributed systems are
1. Layered architectures
2. Object-based architectures
3. Data-centered architectures
4. Event-based architectures
Detailed explanation of layers, objects, and their roles in the layered architecture of distributed systems
In the picture (a) and (b) depict two key processes:
- (a) — downstream (request from the top level to the bottom).
- (b) — upstream (the response from the lower level to the upper one).
Let’s look at each layer, object, and their functions.
(a) 1. Layers and their responsibilities
Layer N (Upper layer is the Application Layer)
** What does:**
- Contains business logic (for example, order processing, calculations).
- Initiates method calls (for example,
createUser(),processPayment()). - Does not know about network details or physical infrastructure.
Facilities:
- Client code (for example, UI, mobile application).
- Server handlers (API endpoints, gRPC services).
Layer N-1 (Intermediate layer — Middleware)
** What does:**
- Provides transparency of distribution (hides network complexity from Layer N).
- Performs:
-
Authentication and authorization (JWT, OAuth).
- Serialization/deserialization (JSON → binary format).
- Routing (load balancing, server selection).
- Caching (for example, Redis for frequent requests).
- Logging and tracking (OpenTelemetry, Grafana).
Facilities:
- API Gateway (Kong, Apigee).
- Service Mesh (Istio, Linkerd).
- RPC proxy (gRPC stub, CORBA ORB).
Layer 2 (Transport Layer/Session layer)
** What does:**
- Manages sessions (connection maintenance, timeouts control).
- Provides reliable delivery (retransmission of lost packets).
- Can include encryption (TLS, SSL).
Facilities:
- Transport protocols (HTTP/2, WebSocket, AMQP).
- Connection Manager (for example, a TCP connection pool).
Layer 1 (The lower layer is the Network/Physical Layer)
** What does:**
- Transmits raw bits over a network (Ethernet, Wi-Fi, optical channels).
- Processes data packets (IP routing, MAC addressing).
Facilities:
- Network drivers.
- Equipment (routers, switches).
2. What is the right way to expand a multi-layered architecture?
1. Adding new layers
If the system becomes more complicated, you can enter:
- Layer N+1 — orchestration (Kubernetes, Nomad).
- Layer 0 — optimization of the physical network (SD-WAN, RDMA).
Important:
- Each new layer should solve ** a specific task**, and not duplicate functionality.
- Avoid redundancy (for example, you should not add two layers for logging).
2. Horizontal scaling of layers
- Layer N-1 (Middleware) can be split into:
-
Auth Layer — authentication only.
- Routing Layer — balancing only.
-
Layer 2 can be divided into:
-
Transport Layer (TCP/UDP).
- Session Layer (session management).
3. Optimizing the interaction between layers
- Minimizing transitions — if Layer N can directly access Layer N-2 (bypassing N-1), this reduces delays.
- Asynchrony — Layer N-1 can cache responses and return them without a request to Layer N.
3. Design errors
- Violation of encapsulation
-
Layer N should not know how Layer 1 works (otherwise transparency disappears).
-
Redundant layers
- If Layer N-1 and Layer N-2 do the same thing (for example, both log requests), it complicates the system.
-
Tight connectivity
-
Layers should communicate through clear interfaces, and not directly depend on each other’s implementation.
Conclusion
- Layer N — business logic.
- Layer N-1 — infrastructure (security, routing).
- Layer 2 — connection management.
- Layer 1 — physical data transfer.
Architecture expansion:
- Add layers only if necessary.
- Share responsibilities (for example, a separate layer for authentication).
- Avoid duplication of functionality.
This is the foundation of modularity and scalability of distributed systems.
(b) Something like OOP
But in a book about distributed systems, such a scheme may hint at:
- RPC (Remote Procedure Call)
- Asynchronous communication,
- Any system where components communicate through strict interfaces.
If it were just an OOP scheme, there would be classes, attributes, and inheritance. Here, the emphasis is on “objects communicate,” which is broader.
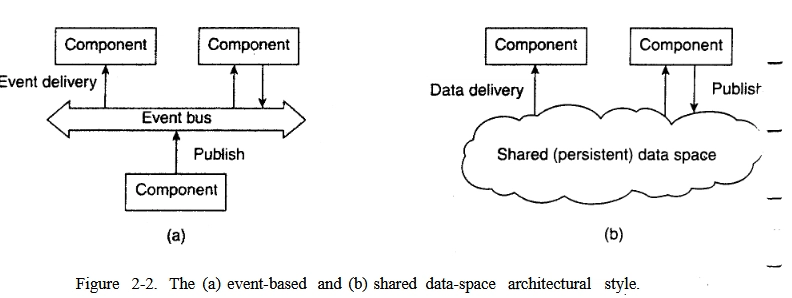
Here is a diagram illustrating two architectural styles of distributed systems (as indicated in the caption Figure 2-2):
- (a) Event-based architecture (event-oriented architecture).
- (b) Shared data-space architecture (shared data space architecture).
Let’s analyze each style in detail.
1. Event-Based Architecture (a)
Key elements:
- Components — independent services or system modules.
- Event bus — centralized event delivery mechanism (for example, Kafka, RabbitMQ).
-
Events — messages that the components publish (
Publish) and subscribe to.
How does it work?
-
Component A generates an event (for example,
OrderCreated) and publishes it to Event bus. - Event bus delivers the event to all subscribed components (B, C, …).
- Component B receives the event and performs its own logic (for example, reserves an item in a warehouse).
Positive:
- Weak connectivity — components do not know about each other, communicate only through events.
- Scalability — New components can subscribe to events without changing existing ones.
- Asynchrony — components work independently.
Minuses:
- The difficulty of tracking the flow of events (monitoring is needed: Jaeger, Zipkin).
- Delivery guarantee (an ‘ack/nack` confirmation mechanism may be required).
Where is it applied?
- Microservices (for example, notifications, payment processing).
- IoT (sensors send events to the central system).
- Reactive systems (for example, updating the UI in real time).
2. Shared Data-Space Architecture (b)
Key elements:
- Shared data space — storage available to all components (for example, Redis, database, distributed cache).
- Components read and write data directly into this space.
How does it work?
-
Component A publishes (
Publish) data to the shared space (for example, updates the order status in Redis). - Component B reads this data and reacts (for example, it sends a notification to the client).
Positive:
- Simplicity — no need for complex event routing.
- Access speed — Data is available to all components at once.
Minuses:
- Tight connectivity — Components depend on the data structure in the shared storage.
- Consistency issues (conflicts when writing at the same time).
- Security — it is necessary to control access to data.
Where is it applied?
- Real-time systems (chats, online games).
- Caching (for example, user sessions in Redis).
- Drawings/CAD systems where multiple clients edit a single file.
Comparison of styles
| Criterion | Event-Based (a) | Shared Data-Space (b) |
|---|---|---|
| Connectivity | Weak (via events) | Hard (general data) |
| Scalability | High (easy to add subscribers) | Medium (recording conflicts) |
| Difficulty | Higher (you need an event bus) | Below (just reading/writing) |
| Usage | Asynchronous workflows | Synchronous data access |
Conclusion
- (a) Event-Based — flexibility and scalability, but harder to debug.
- (b) Shared Data-Space — simplicity, but risks of data consistency.
How to choose?
- If you need to respond to changes (for example, notifications) — select (a).
- If speed of access to shared data is important (for example, online editing) — (b).
These styles are often combined. For example:
- Events (a) for notification of changes.
- Common space (b) for storing the current system status.
For a deeper understanding, read from Tannenbaum about the publisher-subscriber model and multiuser databases.